- Figure 1 in part 1 of this week's notes showed the "textbook" view of a hash table.
-
Figure 1 below shows the lower-level data structure view of the hash table.
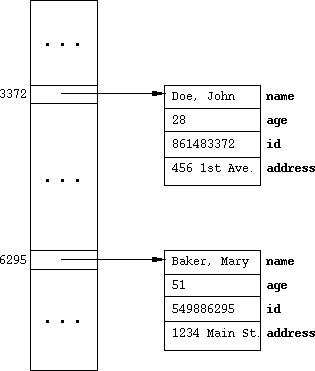
Figure 1: Low-level data structure view of a hash table.
- The concrete representation of the table is the hash table array.
- The array contains references to instances of hash table entry objects.
- In this case, the entries are four-field information records.
- As discussed last time, a key issue in hash table design is determining the best way to resolve collisions when the hashing function returns the same table index for two different keys.
-
There are two major categories of collision resolution.
- Out-of-table chaining (called separate chaining in the book).
- In-table placement (called open addressing in the book).
- The approach for out-of-table chaining is to place colliding entries in a linked list, pointed to by the elements of the hash table array.
- This is the approach most widely used in practice, such as in libraries like the Java Foundation Classes (JFC).
- It is also the approach you will used in Assignment 3.
- Section 5.3 in the book has some sample code; your code for Assignment 3 will differ accordingly, to meet the assignment specifications.
-
The following are basic techniques for implementing hashing methods using out-
of-table chaining:
-
insert(entry)
- compute the hash index for the key of the given entry
- if the indexed location is empty, add the entry as the first element of a linked list pointed to by table[index]
- if the indexed location already has an entry or entries, search the list pointed to by table[index] for an entry with the same key as the entry be inserted
- if such an entry is found, return without doing anything, thereby ignoring duplicate entries
- if there is no same-key entry, splice the new entry onto the front of the linked list pointed to by table[index]
-
lookup(key)
- compute the hash index for the given key
- if the indexed location is empty, fail by returning null
- if the indexed location points to a list, search the list for an entry with the same key as that passed to lookup
- if such an entry is found in the list, return it, otherwise fail
-
delete(key)
- compute the hash index for the given key
- if the indexed location is empty, return without doing anything
- if the indexed location points to a list, search the list for an entry with the same key as that passed to delete
- if such an entry is found, remove it from the list, otherwise do nothing
-
insert(entry)
-
The approach for in-table resolution is to find an empty location in the table
by "probing" through the table.
- On insert, each probe moves some distance away from the location of the collision, searching for an empty location to insert the new entry.
- For lookup and delete, we follow the same probing pattern used for insert, searching for an entry of the desired key.
-
Linear probing
- Linear probing is the simplest form of in-table collision resolution.
- The name comes from the fact that a the linear function is used for the probing pattern.
- Namely, probe(index) = (index + 1) mod tableSize
- That is, the probing search goes sequentially from the collision index, to successive indices below it, wrapping around to the top of the table if necessary.
- The probing stops when the search fully wraps around to the original index, meaning that the table is completely full.
- The HashTable below has the complete implementation details for linear probing.
-
Quadratic probing
-
A potentially significant disadvantage of linear probing is that of
secondary collisions due to clustering.
- A secondary collision occurs when a key K hashes to location L, but L is already occupied by an entry that was put there because of a previous collision.
-
This means that collisions can occur for two reasons:
- Primary collisions are the result of the hash function returning the same index for two different keys.
- Secondary collisions are the result of a hash function returning the index of a location that is filled because of an earlier collision.
- Clustering is the effect caused by linear probing of having a number of collisions "bunch up" around a single location.
- As the clustering increases, the time it takes to perform the linear probing search will increase.
- One solution to avoid secondary collisions is out-of-table chaining.
-
An in-table approach to avoid clustering is to change the probing function from
linear to something else, the most typical case being a quadratic function of
the form probe(index) = (index + i2) mod tableSize, for
i = 1, ....
- Care must be taken when using quadratic probing to ensure that the probing pattern provides adequate coverage of the table.
- A useful strategy is to make the size of the table a prime number.
- As discussed in Section 5.4.2, of the book, this will ensure adequate coverage with the table is up to half full.
- Other strategies are to pick other non-linear probing functions, such as a quadratic residue, that will guarantee full table coverage.
-
A potentially significant disadvantage of linear probing is that of
secondary collisions due to clustering.
-
Double hashing
- A final approach to in-table collision resolution is to use a second hashing function to provide the search pattern.
- That is, we define a probing function of the form probe(index) = index + hash2 + 2 * hash2(index) + ....
- This approach requires careful selection of the secondary hash function, again to ensure full coverage of the table by the probing pattern.
- In the end, out-of-table chaining has be widely accepted in practice, due to its relative simplicity of implementation and the fact that it avoids many of the problems found with in-table resolution.
- A hash table's load factor is defined as the ratio of the number of entries to the table size.
- An important consideration in hashing performance is value of the load factor.
- As the load factor increases, the performance will degrade because of the time required to search collision chains.
- We will discuss some analytic results of hash table performance in next week's notes.
- When a table becomes completely full (with in-table resolution), or effectively (with out-of-table resolution), it is necessary or desirable to reallocate the hash table array.
-
This entails:
- allocating a new array, of say twice the size of the original
- re-entering all of the existing keys by rehashing them all
- Attached to the notes are the code listings for a HashTable class, plus auxiliary classes for hash table entries, exception handling and testing.
- We will discuss the details of these classes in lecture and further in lab.