CPE 103 Hashing Lab 2
For this lab, you will be writing a formal
lab report. You may take notes in your lab
notebook, but you will be submitting the written report on the due
date. You will complete the lab activity with a partner, but
each individual writes their own report.
Warning: These instruction do not tell you everything you need to
know to solve this problem. Some details are intentionally
omitted; you have to figure these out on your own. Tip: Don't
reinvent the wheel. You don't need to write your own hash function.
Ask the instructor if you get
stuck, not other student teams.
We will be doing an experiment to determine if the nature of the
input data effects the performance of a hashtable. Begin by
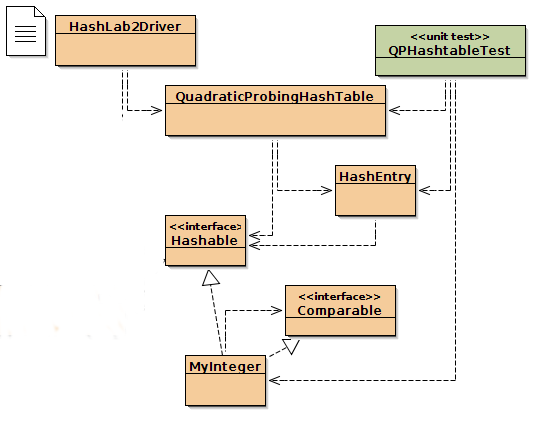
modifying the author's Quadratic Probing hashtable class from the
previous lab so that it will count the number of probes that are
performed to insert an item in the hashtable. An item inserted with
no collisions count as one probe. Each spot that collides counts as
one probe.
Manually compute the number of probes that should result from the
numeric data in exercise 1 of the previous lab. Run the tests to
verify your probe counter is working properly.
Draw a diagram of the hashtable of size 23 that would result from
inserting these Strings in the following order: A, W, X, Y, CM, CK,
BD, H, MOB, BD. Manually compute the number of probes that should
result. (Tip: You can use the BlueJ IDE to assist with this).
(Tip: Don't invent your own String hash function. Use the one Weiss includes
in his class.) Check
with the instructor for the correct answer. Run your probe counter
with this data and verify that it is working properly.
Experiment:
Consider the effect of the following three data sets on the
performance of the hashtable:
- A common unix word dictionary, in alphabetical order:
http://www.robblackwell.org.uk/wp-content/words
Use the "wc" command to find out how many words it
contains.
- The text
file
containing "Huckleberry Finn". Modify the file in a text editor so it has
exactly the same number of words as the dictionary file.
- A common unix word dictionary, in random order:
(Tip: The unix sort command has a -R flag to randomly shuffle
the input).
Make a prediction based on your theoretical understanding of
hashing. Which would create the most collisions?
Why? (You should record your prediction so you can include it
in your lab report before proceeding).
Now set the capacity of the table to be twice as large as the number
of words in the dictionary file. (Why does this matter?)
Write a driver to run the experiment, hashing all three files and
recording the total number of probes. The driver should NOT filter
duplicates from the input file. (If "the" appears twice, you should
call insert twice.) You might also print the number of
words processed, as a confirmation.
Calculate the average number of probes by dividing the total by the
number of words.
Do the results match your prediction? Is the average about the same
for all input types? If not, which is longer? Explain why.
Submit your formal lab report (including data collection, analysis,
conclusions, and source code) as a PDF to PolyLearn by the due date.
Submit your printed lab report (including data collection,
analysis, conclusions, and source code) at the next class
meeting.
References