Lattice Noise Deformer
Kishan Patel
CPE 458
6/11/2015
Overview
The Lattice Noise Deformer (“latticeNoise”) is an existing Maya plugin that deforms a list of selected meshes based on random noise applied to a lattice circumscribing them. The objective of this project was to implement threading, vectorization, and Xeon Phi offloading to the main compute node to achieve a speedup compared to the existing serial plugin.
Vectorized Lattice Noise Deformer
I was not able to achieve scalable parallelization or offloading. I was able to achieve a roughly 10% speedup through serial optimization such as inlining commonly called functions and refactoring. I also achieved a roughly 20% speedup through SOA refactoring, cache alignment, and vectorization. All in all I was able to speed up the code 30% compared to the reference.
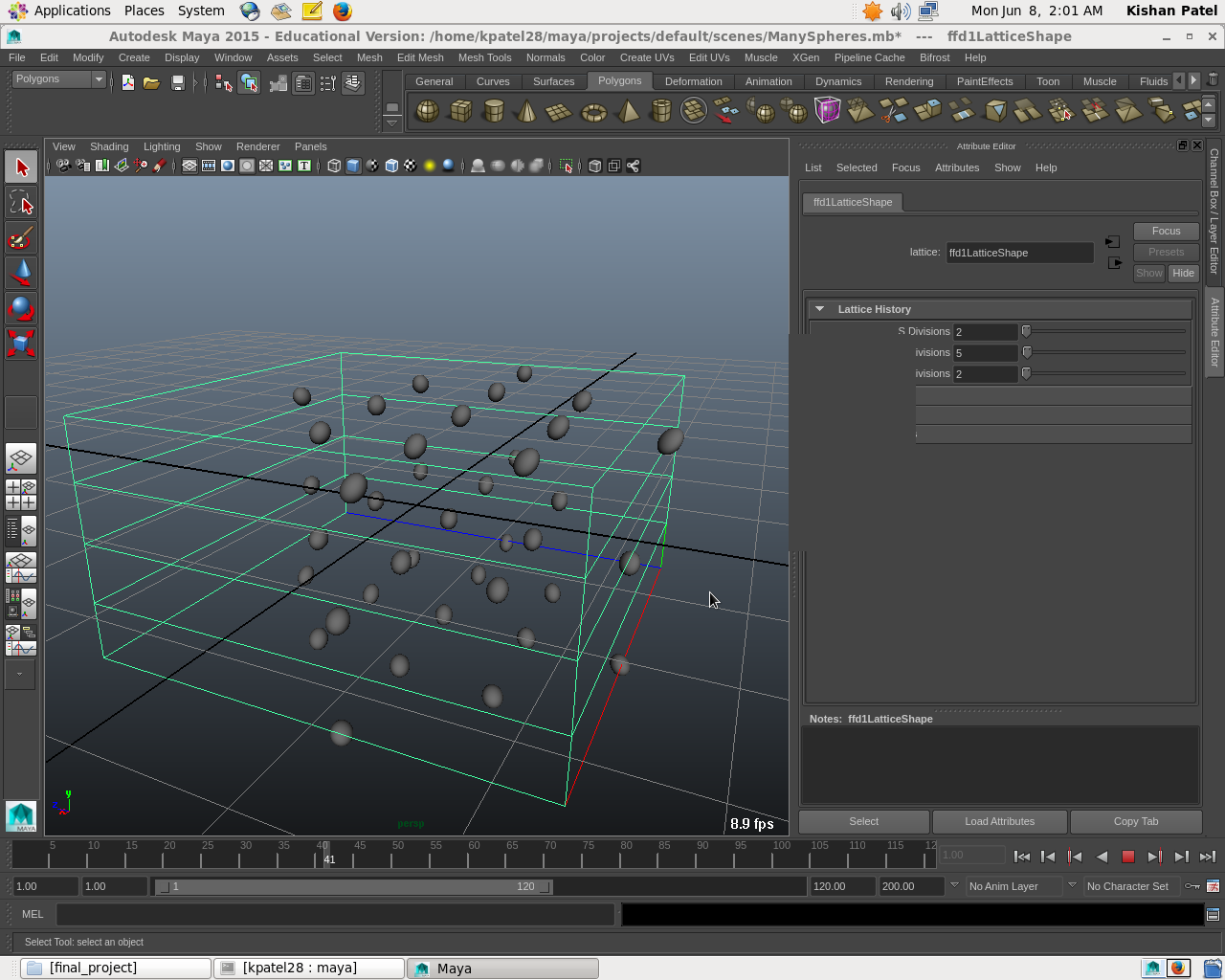
39 Sphere Test
Results
The main success I had with this project was vectorization. I was able to align all the knot arrays to a cache line each in the noise::atPointAndTime method. Combined with the __assume_aligned directive, I achieved a speedup of 20%. I did not attempt to parallelize this loop which computed the 255 splines as it required in order execution. Even if it was possible to refactor the code, I reasoned that my time would be better spent attempting to parallelize the main compute node loop (which looped over the lattice intersections).
Forcing vectorization in the compute node loop did not result in any speedup. I spent most of my time working on this project fruitlessly trying to parallelize the compute node loop for some degree of speedup.
Problems
One of the major setbacks I had with this project had to do with the MEL script. The script that came with the plug-in apparently did not call the compute node of the program - it instead called Maya API functions through MEL strings. This took some time to figure out, primarily because I did not know this could be done with Maya and the fact that the output was correct confused me. The obviously hampered my development because the code that I was writing was not actually being tested and resulted in much confusion. My lack of understanding of parts of the Maya API certainly exacerbated the problem.
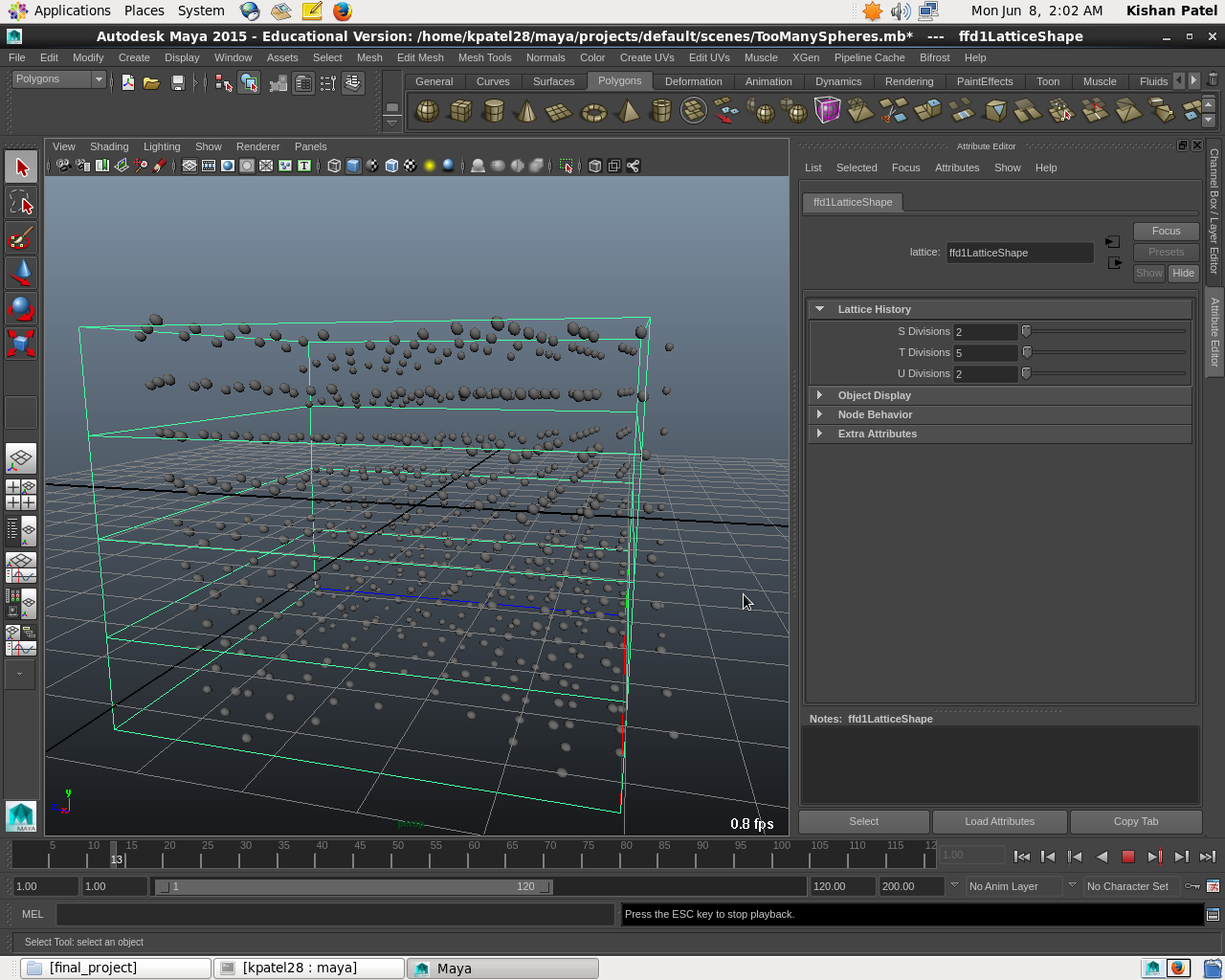
585 Sphere test
The other major setback I had was the fact that I simply could not get the compute node to scale well when parallelized. In retrospect I may have been mistaken in my initial assumption that this was a good candidate for parallelization. I entered the project with no animation experience or knowledge of splines. What I did know from deconstructing the existing plugin was that there were 255 spline operations per iteration of the compute loop, and that each spline consisted of 34 floating point operations. With the default number of lattice intersections (20), we get 173400 total floating point operations for the compute node loop. This results in decent a arithmetic intensity value of 722.5.
AI = (numSplines * numFPperSpline * length * width * height) / (length * width * heigth * sizeOfTuple)
Of course, what I failed to see was that the above equation scales poorly with more data - it always results in a constant value ( O(1) ).
One major folly that I had unconsciously The important factor would have actually been the granularity of the lattice. Even so, while raising the lattice granularity raises the number of computations to allow slightly better scalability, it does not increase arithmetic intensity by the very nature of the problem.
Dependency Graph
Conclusion
This was the one of the most difficult programming projects I have ever worked on. In retrospect, this project was an excellent case study of failure in parallelization and it was an excellent learning experience. I had spent twenty-eight hours overnight on campus in order to achieve a parallel speedup. In my desperation to make parallelization work, I was not lucidly analyze important matters related to parallelization. If I had to do this again, I would have chosen a project that I had some existing background understanding of (such as the n body problem) and that actually scaled well and had good arithmetic intensity. The fact that I had to switch my project objective to the Lattice Noise Deformer only 36 hours before the presentation caused me to neglect the rigorous analysis I would have done for the proposal. This was probably the most significant thing I will take away from this experience: that complexity and scalability analyses for parallelization projects should practically be required before truly starting them.