Parallel Cloth Solver
Problem Introduction
For our project, we implemented a cloth solver, using a model based off the stretch and the strain of the cloth. Our implementation is based off of the paper “A Simple Approach to Nonlinear Tensile Stiffness for Accurate Cloth Simulation[1]”. This simulation method allows for interesting cloth physics, and offered some attractive complexity. When we initially picked the project, we had a small idea of how complicated the mathematics are. As we completed it, we realized issues with our approach, and other approaches the the problem.
Cloth in simple simulation
Problem Implementation
Due to the lack of library support, and knowing we’d be offloading, we chose a simple simulation method. To simulate one step of the cloth, we calculate the current forces on each vertex due to the stress and strain of the cloth, multiply by a small time step (0.0005 seconds) to get the new velocity, and then update the position by multiplying the step again.
Our forces are calculated with a parallel loop. Each thread handles a chunk of triangles, and calculates the strain and stress on each vertex in the triangle groups. This is our biggest race condition, and to ensure accuracy in our simulation, we added atomic pragmas on our addition lines. Unfortunately, this stopped us from vectorizing this loop.
Once all the forces are calculated, we needed to integrate the positions of the vertices. This ended up being our biggest roadblock, and we ran into it without realizing how expensive locking all the threads were. If we were to implement this project again, we’d take a more careful look into updating the vertex positions.
We were very concerned with the amount of data needed to simulate the cloth. We didn’t want to send the vertex positions, velocities, indices, and the rest of the simulation data over every frame. We used the #pragma offload_transfer to handle sending data to and from the card without performing any simulation.
Our initial data transfer
During simulation, only a list of vertices to lock, and the time steps are transferred to the card. On a simple cloth, (64x64) Our total simulation transfer was slightly under a kilobyte.
Our very small transfer, and our retrieval step.
Due to the simulation we used, we found that a time step of 1/60th of a second was too fast. We had to run multiple simulation steps per frame. Initially, we thought this would be a win for algorithmic intensity. In reality, we found that the synched update step ended up eliminating all gains.
Project Organization
Our project is organized into three main sections: OpenGL boilerplate, the Cloth class, and the Cloth Force Integrator class.
Most of this code is built off of previous OpenGL projects. Classes allow for lights, cameras, and action in a main runtime loop. None of this code is optimized or vectorized.
The Cloth class holds all the information necessary to build the initial cloth mesh, and display it. Any calls to cloth simulation and interaction run through the cloth class.
The Force Integrator class holds all the information required to simulate the cloth. All optimization and offload work is done here. This class is fairly primitive, and doesn’t use stl or math library functions.
Profiled Runs
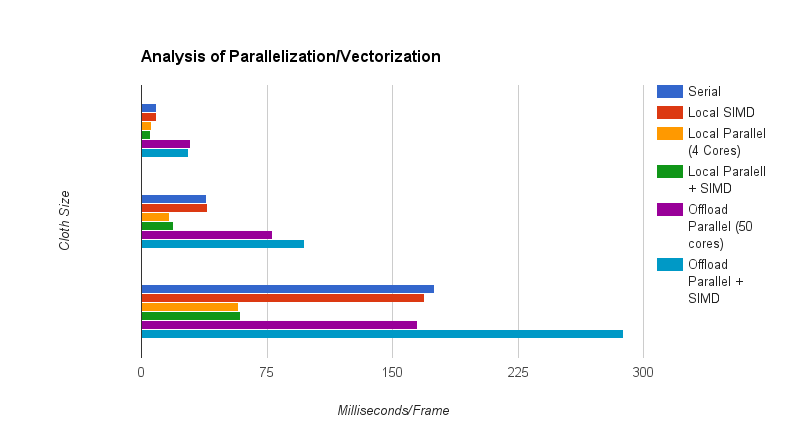
Our metric used is seconds per update. Each update consisted of advancing the frame 1/60th of a second, and running 33 steps per the advance. SIMD operations were applied when speedup was predicted to be 1x or greater (Only in a serial section). Measurements were taken at cloth sizes of 32x32, 64x64, and 128x128. Averages were taken over many (>10) sampling points. All runs were compiled with -O3 optimization.
The following configurations were tested:
Offload Results
Our initial goal of building a good cloth simulator was met, our simulation looks fairly pretty, and runs decently with lower resolution cloths. However, our offload left much to be desired. We’re still exploring why our offload is so inefficient, but our best bet is the time it takes to start and stop the threads on the Xeon Phi.
We are very pleased with the low data transfer rate, and would explore this offload technique again for N-Body simulations, Stencils, or other more computationally expensive simulations.
CUDA implementation
In addition to offloading our work to the Xeon Phi, we also completed a CUDA version of the algorithm. In order to adapt to the simulation, we had to restructure our core algorithm. Instead of atomics, we allocated arrays to hold force information per thread. This allowed us to run many threads in parallel, without the need for expensive locks. We only had time for an initial prototype, but results were extremly promising.
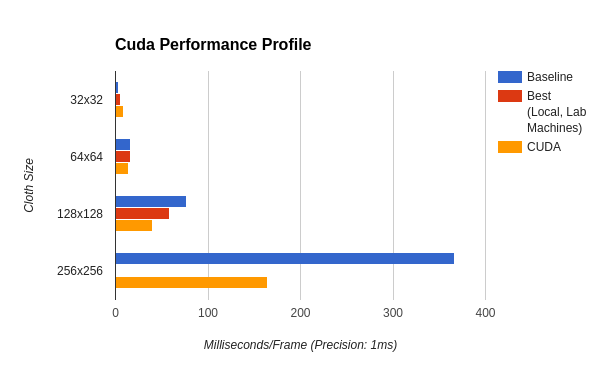
Our CUDA runtime data was created on a system with an Intel Core i5-4670K (3.4 GHz Quad Core), and an NVIDIA GeForce GTX 770 (3,213 GFLOPS [2]). Below are our results:
(Note, at 256x256, our simulation destabilizes. Benchmarks were only made to show scaling)
CUDA ended up being very fast for a middle-of-the-line CPU and GPU. The data transfer ended up not being as big as a problem as we assumed. We still need to explore using our new scan-based algorithm on the Xeon Phi, as it completely eliminated any atomics.
In order to perform a simulation on the GPU, we had to transfer the positions and velocities of the cloth back and forth every step. We were able to avoid this problem on the Xeon Phi, but have not looked into optimizing data transfer on the GPU.
We used Nvidia Visual Profiler to gain more information on the efficiency of our operation. We found that our kernel ran at 1119 GFLOPS for a 128x128 sized cloth.
Observations and Thoughts
Our SIMD performance left much to be desired. Despite aligning data, we saw little to no gain with SIMD operations. Most of our SIMD code ran in serial, which would explain the lack of fast operation on the Phi. In addition, our SIMD operations generated many peel and remainder loops, which led to more inefficiencies.
We were able to write code to smoothly transition between offloaded data and non-offloaded data. Although this code is not very useful in our current simulation, or in practical high-computation areas, it is useful for testing and demoing. We found that #pragma offload_transfer was a nice tool in our toolkit, allowing us to set up and move data as necessary.
We had issues with class variables, vectorization, and offloading. Our biggest problem was retrieving data following an offload. Somehow, our class pointers were reassigned on entering an offload section. This may have something to do with how the Xeon Phi deals with C++’s hidden ‘this’ pointer when using a class variable. Our workaround involved copying the pointer value of the arrays defined in our class into local pointers, and then reassigning the class array pointers after an offload. We’d like to explore why this happens later, but have learned a good workaround.
Our CUDA scan algorithm may improve SIMD operation, since the main loop no longer uses atomic locks to sum forces. If we had more time, we would attempt to offload the algorithm, and compare performance.
Conclusion and Future Work
Although cloth simulation can be computationally expensive, we needed a more intensive simulation to make it worthwhile. The Frame-by-Frame nature of this simulation makes it difficult to parallelize, but the ability to do it all on an offloaded system provides a great amount of worth. Including other per-triangle forces (wind, density, proper dampening) and computationally intensive features (Self intersection), could go a long way in increasing the value of offloading the cloth. CUDA performance, on the other hand, ended up being very good. Several games have already offloaded their physics calculations to the GPU. NVIDIA even provides their own solver (PhysX [3]) to perform these kinds of calculations. For simple simulations, the best option appears to be GPU or CPU.
Created By
Zach Arend
Kyle Piddington
Paul Sullivan
Citations
[1] Volino, Pascal and Nadia Magnenat-Thallman: A Simple Approach to Nonlinear
Tensile Stiffness for Accurate Cloth Simulation (http://dl.acm.org/citation.cfm?id=1559762)
[2] http://www.techpowerup.com/gpudb/1856/geforce-gtx-770.html