
About
Optimizing ray tracer with POSIX Threads and Linear BVH
For CSC 473 final project, I choose to focus on just pure optimization. We all know that ray tracing is embarrassingly parallelizable since each pixel is processed independently; therefore, one might think to do this on the GPU. However, ray tracing is also extremely branchy in nature, which is terrible for GPU. Big companies like NVIDIA have been tackling the real-time ray tracing for a while since the divergence problem is shown to be a behemoth task to tackle down. I decide to parallelize my ray tracer on the CPU with the help of POSIX Threads (pthreads), which is native on Linux (or any UNIX system). Furthermore, a bounding volume hierarchy (BVH) structure, which is another popular optimizing technique for ray tracing, is also implemented.
Features
Multithreaded draw with pthreads
There are 8 threads being launched, and each asks for which pixel to process from a Job Queue system.
Multithreading on the CPU is a bit simpler than on the GPU. Each thread can share the same memory space, and recursion is allowed which is typically what a ray tracer utilizes a lot for bouncing rays. You can think of a thread as a worker, and the more execution threads you have the more workers doing your task. The first easy implementation of multithreading is to launch multiple threads at the same time, and each thread processes 1 pixel. With 8 execution threads in the draw loop, you can advance 8 pixels at a time. However, this is not the optimal solution because each thread would have to wait for each other to finish before getting new work. Thus, the throughput is not 100%, and a lot of threads would be spending most of their time idling. To remedy the problem, a Job Queue system is implemented. With this, 8 threads of execution will never stop and constantly ask for new job once they finish processing their assigned pixels. If there is no work left in the Job Queue, each thread would stop.
Morton Code Linear BVH tree
A BVH linear tree (using a contiguous memory array instead of random memory location) is also implemented as an acceleration structure to further improve rendering time. The idea is to drastically minimize the number of ray collision test against objects in the scene. Without an acceleration structure, the ray casted from the camera would have to check with every single collidable objects in the scene, and this is extremely bad for performance. If a ray is heading toward an object in a specific area of the scene, then the ray would only have to check for collision with the area hierarchy that is bounding only that region of space.
There are many schemes to partition the scene area to different hierarchies, a.k.a BVH tree nodes. The scheme I have chosen is to split the area based on the Morton encoding of the centroid of each object’s bounding volume. This scheme is great for parallelization because building a hierarchy typically uses a branchy approach (such as Surface Area Heuristic), and this method converts the partitioning problem to a sorting problem, which is relatively less branchy. After the Morton codes are sorted, codes that are close to each other can be grouped to form BVH nodes, and codes that are inside each node, again, can be grouped into smaller nodes.
After the tree is built, it also gets flatten to an array. The easy implementation of a binary tree, like our BVH tree, is to just dynamically allocate random chunks of memory; this is terrible for cache locality, and since our tree is going to be traversed a lot (many rays casted from the camera and also bouncing rays from different materials), it is worth the time to use a contiguous memory to represent our tree.
Due to time constraint, this feature in the current state does not play well with transformations, so if there is any transformation specified in the POV-Ray file, the ray tracer would not use the BVH tree. Furthermore, the BVH tree can only support spheres and meshes.
Benchmark
Setup
I have 2 scripts for the setup. The first script is to generate POV-Ray test files. It starts out to have only 7 reflective spheres in the scene, and incrementally, the script would keep adding 7 spheres to the POV-Ray files. For instance, first test would have 7 spheres, the second test would have 14 spheres, and this keeps on going until I have 50 POV-Ray files to test (the last one has 350 reflective spheres).



The second script is to execute the ray tracer 50 times, each time rendering 1 POV-Ray test file generated from the first script.
I tested the ray tracer (compiled in Release mode with -O3 flag applied) on the Linux 127x03 server with these 4 configurations: (1) with nothing, (2) with BVH only, (3) with 8 threads Job Queue only, and (4) with everything (BVH + 8 threads Job Queue).
Love me some numbers (and graph)
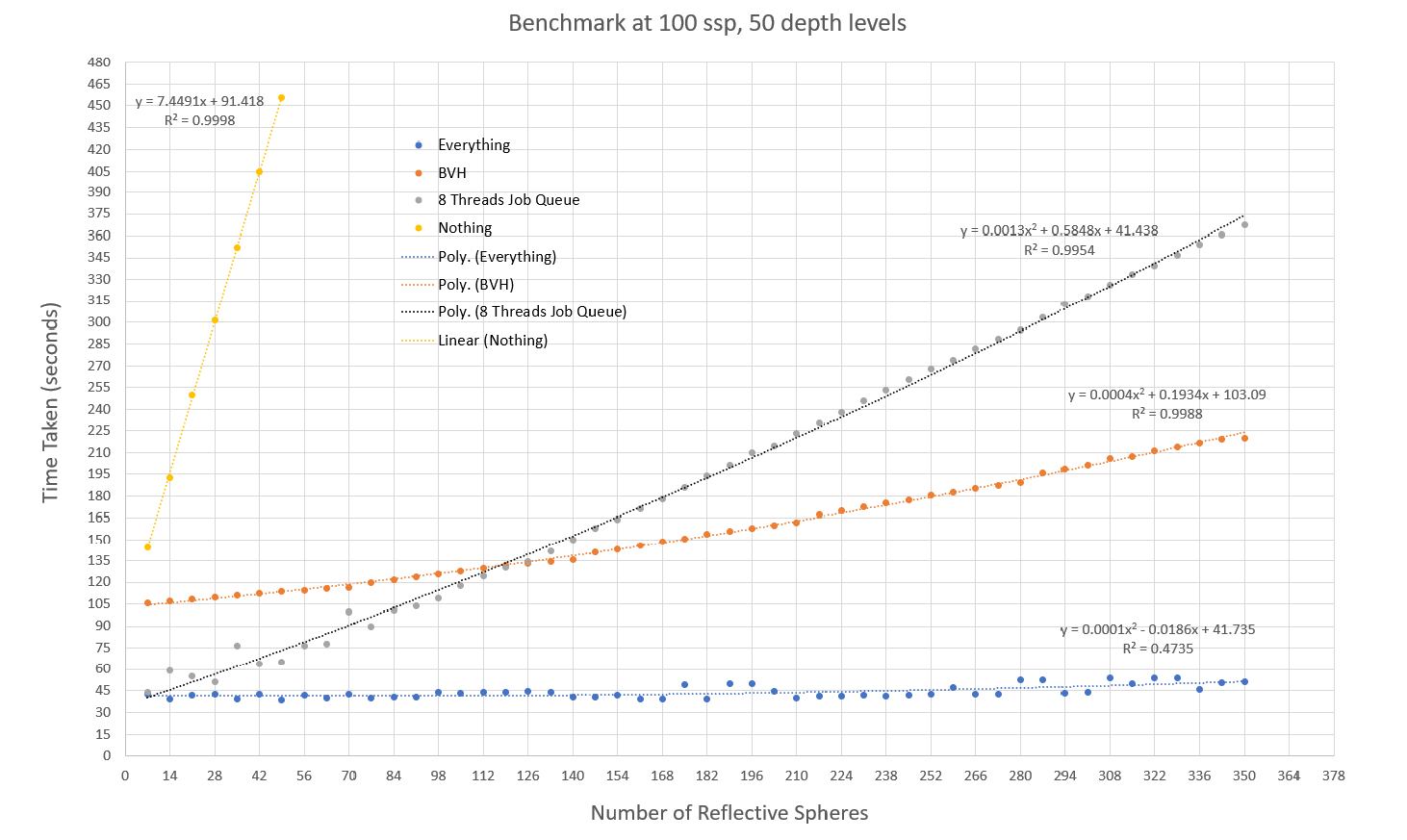
With nothing (yellow dots and line), we can see a big O(n) problem right there, as the time scales super linearly with number of spheres added. With 8 threads and Job Queue only (grey dots and line), we can still that O(n) problem, but timing is a bit better since we have more workers to work as inefficiently as before. With BVH (orange dots and line), the problem is looking more like between big O(log n) and big O(n), since in the worst case BVH traversal still has O(n) execution time. Of course, we save the best for last, with both BVH and 8 threads Job Queue (blue dots and line), the problem is looking like O(1).
References
- Physically Based Rendering
- Thinking Parallel, Part III: Tree Construction on the GPU
- Of course thanks to Dr. Zoe Wood. Wish you all the best.