MapReducing Raytracing with Hadoop
Prentice Wongvibulsin
CPE 473 - Advanced Rendering
Dr. Zoe Wood
Fall 2010

Figure 1 - Render Example, Crazy (800x600px)
Rendered using 2 nodes on Atom-based cluster (no optimization).
Runtime: 0h19m9s (vs. 0h31m0s on a MacBook Pro)
Alternate Version: 1280x1024px
Rendered using 6 AWS Elastic MapReduce Instances
Runtime: 0h32m0s
Summary
This project distributes the computationally intensive task of Raytracing across a Hadoop cluster.
We break up the work into rows. Each map is responsible for computing a row. Because the key-value pairs in the Hadoop system are plaintext, we use base64 encoding to preserve the integrety of the data. These intermediate maps are then sent to the reducer which decodes the base64 strings and combines the rows into a tga image. Then, it encodes the entire tga image with base64 encoding again to preserve the integrety when it is stored in the Hadoop cluster. Figure 2 visualizes the datapath and the encoding/state of the data at each stage.
The Hadoop MapReduce job is written in Python and executed using Hadoop Streaming. I ran jobs on a low-power Atom-based 3-node Hadoop MapReduce cluster and AWS Elastic MapReduce instances.
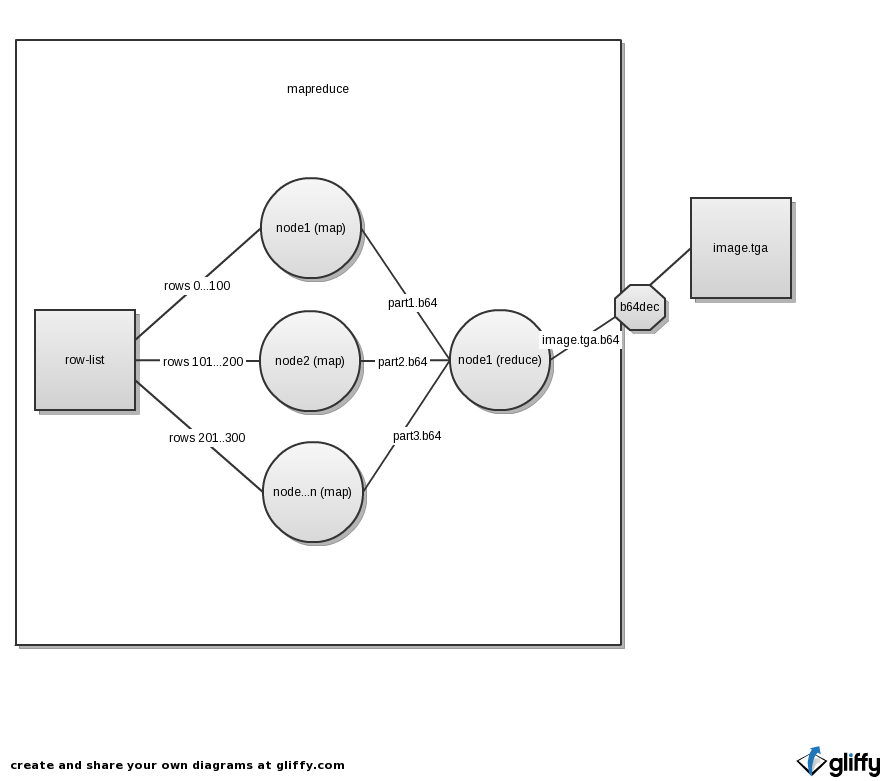
Figure 2 - Map Reduce Diagram

Figure 3 - Render Example, Spheres (800x600px)
Rendered using 2 nodes on Atom-based cluster (no optimization). Runtime: 0h1m11s
Related/Reference Materials
3-node Atom-based Cluster

AWS Elastic MapReduce Management Console