
The reason complex 3D environments are possible in real time is because of good scene management. You have to figure out what not to draw. Most game engines have this data statically precomputed.
|
|
|
Games like Doom and Quake use BSP trees which take time to compute after working on the level. This is annoying if you are a designer and want to test the level quickly. Also the data is completely static. Destructible environments are only possible if you say, "THIS WALL, YOU WILL BE DESTRUCTIBLE!!!"

|

|
Portal culling is another example. It's still static. The level designers have to manually place these all over the place.
You can have a much simpler data structure such as an octree or even just a simple 3D uniform grid. Then do View Frustum Culling on it. Here's a demo from the Unity 3D engine.
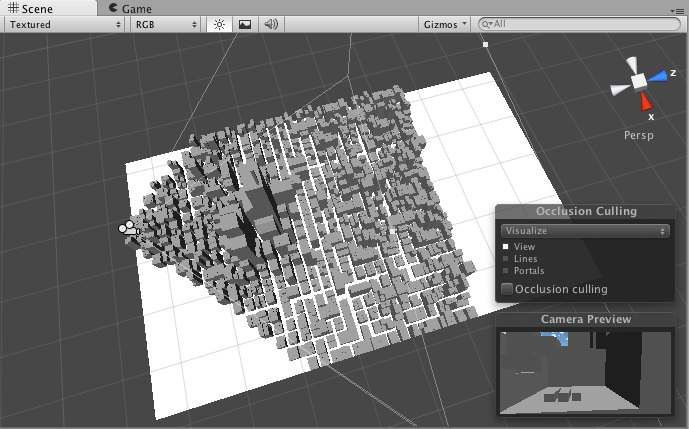
With the help of hardware occlusion queries you can also not draw things that are completely occluded. This way you aren't wasting bandwidth sending geometry data to the GPU and forcing shaders to do pointless rendering of invisible objects.
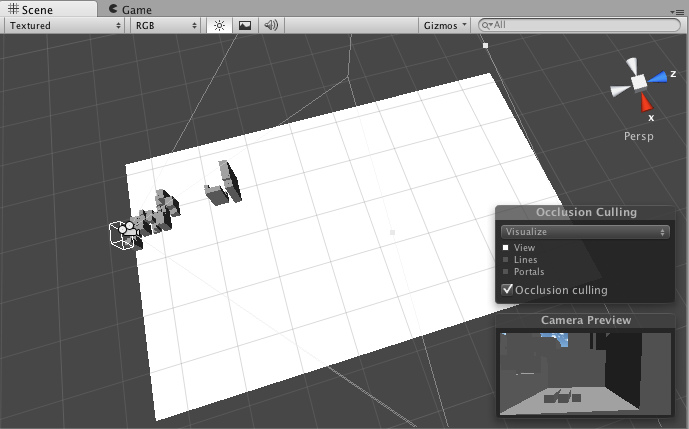
Games like Battlefield 3 and Crysis work similarly. This is what makes Crysis's famous WYSIWYG sandbox editor possible. The environments are completlely dynamic and updated on the fly. They avoid as much precomputed data such as lighting and visibility as possible.

|

|
According to some of their technical documents, they use software rendering to do occlusion queries. Using hardware occlusion queries is a bit complicated since you have your CPU side game code making asynchrnous calls to the GPU to do these things. They do software occlusion because they can do some queries and use the results in the same frame.
My idea is to use hardware occlusion queries to do the same thing. The GPU is very good at drawing lots of redundant things that most likely wont end up on the screen anyway. It's still a good idea to not draw EVERYTHING when you have a huge environment with over a kilometer viewing distance.
My technique first figures out which 3D grid cells are visible from the current viewpoint. It then only draws objects in those 3D grid cells on to the screen.
Modern level designers typically build levels out of a library of models, kindof like lego bricks. This helps with instancing of meshes and reducing memory usage, and is also really good for occlusion culling. The level designers would place large occluders, such as terrain, buildings, etc... Then they'd place all the tiny objects that add detail to the world.
The first pass traverses the view frustum front to back and renders simplified geometry for the large occluders. Color write is off at this point. Only depth write is on. The simplified geometry for large occluders must be fully containable within the actual visible geometry that will later show up. This is used to roughly estimate if other objects will pass the hardware occlusion queries. So as you are drawing these large occluders, you are filling up the depth buffer for things to fail occlusion queries against later, and you'll know they are occluded.
You traverse the view frustum front to back by traversing the 3D uniform grid. For each grid cell you traverse, you draw the large occluders. You then disable depth write, and draw the cube for the cell itself while issuing an occlusion query for it. If the occlusion query passes, meaning pixels passed the depth test, then the cell is roughly visible.
After all this, you go through all cells determined to be visible and render all objects in those cells. Only first you don't render them just yet. You disable depth and color write, issue an occlusion query, and render the bounding box for the object. Then you use the results of this query next frame. If the bounding box passed the query, you issue an occlusion query and render the actual object with color write and depth write on. Otherwise you test with the bounding box again. You now are rendering the actual object but are still using it to do an occlusion query as well. If an object's bounding box keeps passing the visibility test one frame, but failing when you are rendering the tiny object next frame, you basically oscillate back and forth between rendering one then the other. This still offers an improvement in performance overall since you filter out so much more objects that end up never being visible. You do end up having objects popping in a frame later, but it's completely unnoticeable at interactive framerates since it's such a small time interval. You also end up drawing a whole lot of redundant objects, but modern hardware is more than capable of doing this. Since you have depth write and color write off for most of these queries, and are only drawing simple bounding boxes, the performance hit is almost negligible. The CPU would most likely take more time figuring these things out, even with some clever algorithm, than the time it takes for a modern GPU to render all these objects and return the occlusion query results.
Here's an image of what I managed to finish so far. The bottom viewport shows that a very small amount of objects is actually being sent to the renderer to draw. The scene contains 1045 objects, yet on average about 30 are visible.

Fast and Simple Occlusion Culling using Hardware-Based
Depth Queries
Dynamic Scene Occlusion Culling using a Regular Grid
Doom Engine Review
GPU Gems Chapter 29. Efficient Occlusion Culling
Battlefield 3: Culling The Battlefield
Cry Engine Technical Docs: Culling Explained
Unreal Engine 3 Docs: Visibility Culling