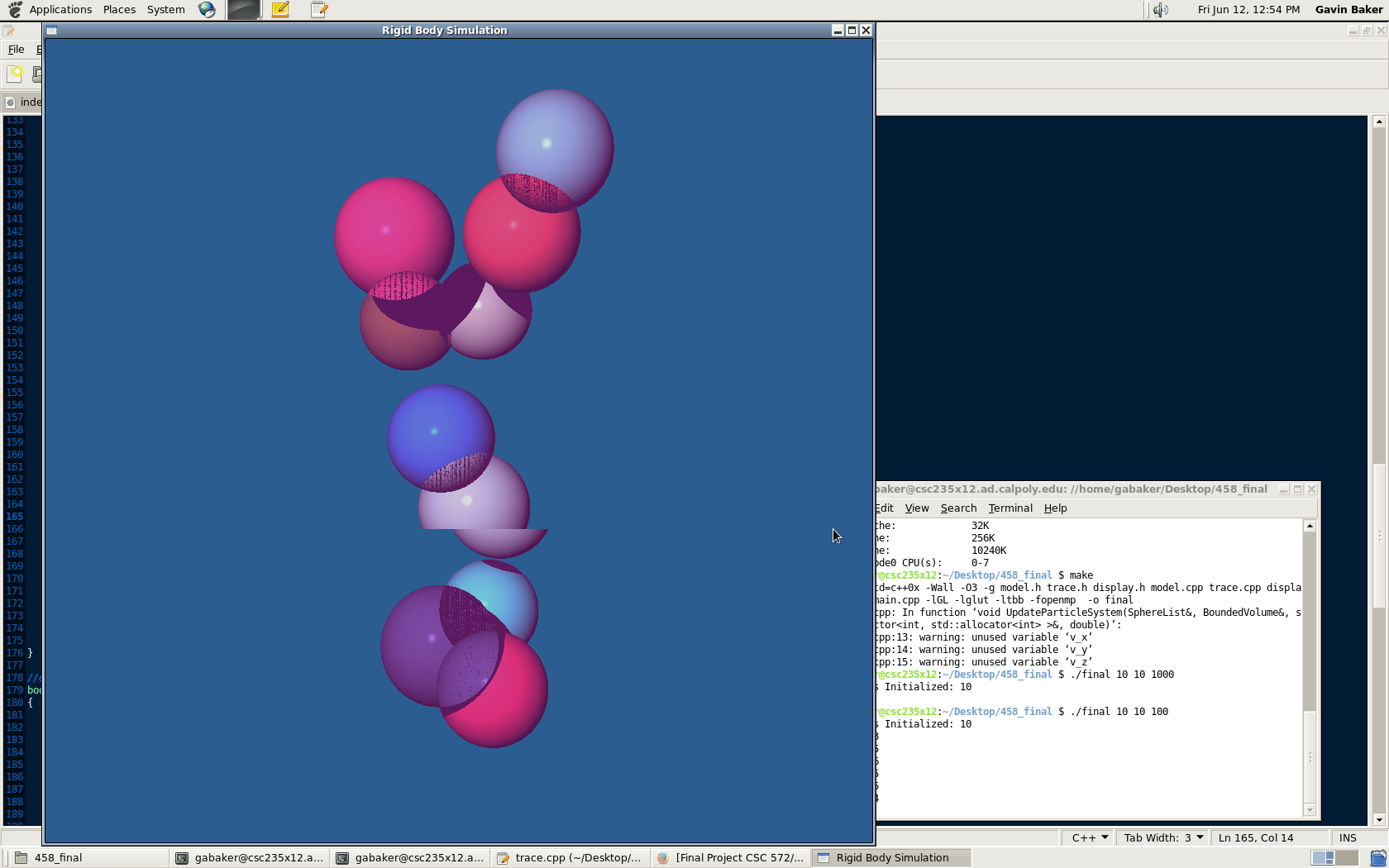
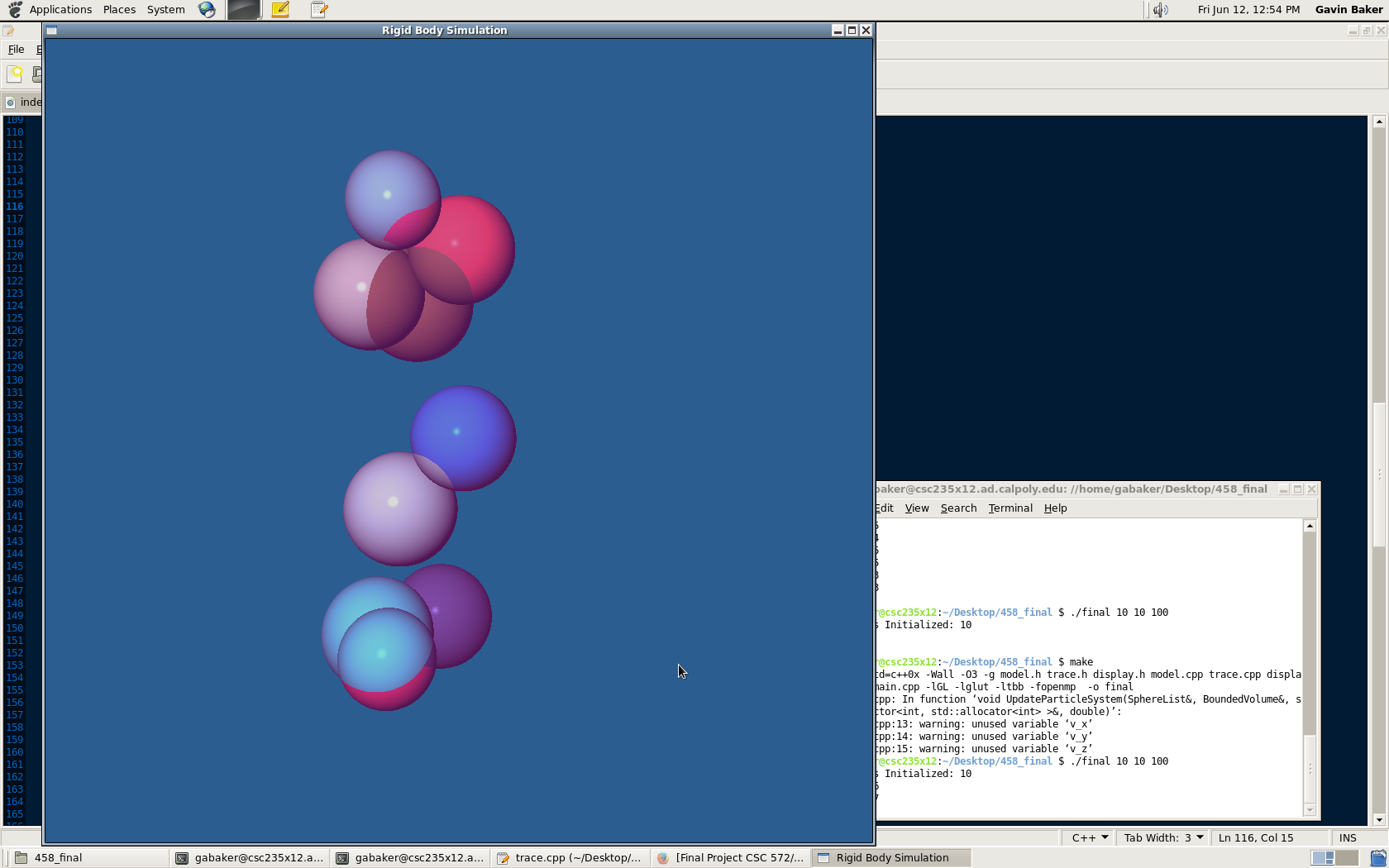
The left side displays the program with shadows enabled and the right side shows shadows disabled.
Developed by: Gavin Baker
CSC 572/458
Spring 2015
This project is a cross over between the Cal Poly Graduate Graphics (CSC 572) class and the new Parallel Animations class (CSC/CPE 458). This project seeks to improve my understanding of advanced graphics topics (spacial data storage and ray tracing) as well as explore the performance gains that can be made by utilization common parallel computing libraries (openmp/tbb). Ray tracing is a method of rendering a scene and its lighting within a scene of objects. This method has the potential to produce a very accurate reproduction of real world lighting/object color. Its limitations have long been the time it takes to render complicated scenes that contain many objects/surfaces. In this project I explore how many objects, in the form of spheres, can be rendered at reasonable frame rates (real time vs interactive). While spheres are simplier to represent than triangles/planes this project focuses on the spacial data structure used to store the scenes objects rather than supporting a wider variety/type of object.
Interactive: A frame rate of atleast 10fps is considered an interactive frame rate.
Real Time: A frame rate of atleast 30fps is considered a real time render.
1 sphere with radius = 100: 60fps
10 sphere with radius = 100: 40fps
15 sphere with radius = 100: 30fps
100 sphere with radius = 100: 10fps
1 sphere with radius = 10: 60fps
10 sphere with radius = 10: 40fps
100 sphere with radius = 10: 15fps
1000 sphere with radius = 10: 11fps
2200 sphere with radius = 10: 10fps
10000 sphere with radius = 10: 6fps
1) CPU Parallelism
The main parallelism within this program takes place in the actual ray tracing function. Initializing the spheres and building the BVH requires many atomic operations and therefore cannot be easily or scalably done in parallel. The ray tracer however casts many rays into the scene, each of which must look for intersecting objects. Each ray within an iteration of the casting function is independent from eachother and therefore can be split up and put on a seperate thread. Because each ray may or may not intersect an object we use the dynamic scheduler with blocks of rays to load balance the variations within the scene.
2) Vectorization
While I used various pragmas to suggest possible areas for vectorization much of the ray tracing algorithm contains complicated conditional logic and function calls within each loop. I was able to inline some of the function calls to improve the chances of having the compiler vectorize but the compiler would not vectorize the code. Forced vectorization did not improve performance.
3) Xeon Phi Offload
The Intel compiler (in offload mode) does not support glut/opengl libraries which made offloading it to the co-processor very difficult. A significant code refactoring was done to move all Xeon Phi related code/files to seperate functions and files. In the end the lab computers were shut down before I was able to peformance test my Xeon Phi version of ray tracer. I suspect that because the BVH must be rebuilt every time you update the "rigid body system" that the CPU peformance might have been comparable. Each of the Xeon Phi's 57 cores have significantly slower single threaded performance than modern CPUs. Building trees in general is difficult to do in a multithreaded system. Because BVH's require a sort by axis to create each node/level of the tree, it is impossible to multithread the tree construction. As a result we would most likely find that the time to ray trace a single frame would improve with the higher core count of the Xeon Phi but the cost of creating the BVH would counter any performance gains. Additionally, creating the tree on the CPU and offloading it to the cpu was not possible because of the lack of data locality of tree nodes on the host. While there are methods to "flatten" the structure of a binary tree into an array and therefore allow it to be built on the cpu and transferred to the Phi, this was outside the scope of this project."
1) Shadows were implemented for the ray tracer as well but not using the BVH intersection. Additionally enabling shadows gave the following "feature:"
The left side displays the program with shadows enabled and the right side shows shadows disabled.
Given additional time, I would like to be able to peformance test my second implementation (Xeon Phi) to determine if a speedup could be achieved. It is likely that the time it takes to build the BVH would outweigh any benefits of parallelizing the ray trace but as mentioned above there are methods for refactoring a BVH that could be implemented given sufficient time. Certainly at lower scene object counts the benefits would have been substantial. For future work I would like to optimize and performance test my Xeon Phi code. On the Graphics side I would like to continue improving the ray tracer to fix shadows and implement radiance. Also building a camera for the scene would enable the viewer to see the rendered frames from various views.
1) Compile the executable
2) Type the following command with its cooresponding parameters: "./final sphere_count leaf_size sphere_radius"
3) Enjoy the program!
There are three options for compilation:
-Nieve Object Search: "make nobvh"
-BVH Object Search: "make bvh"
-Toggle between Nieve and BVH: "make"
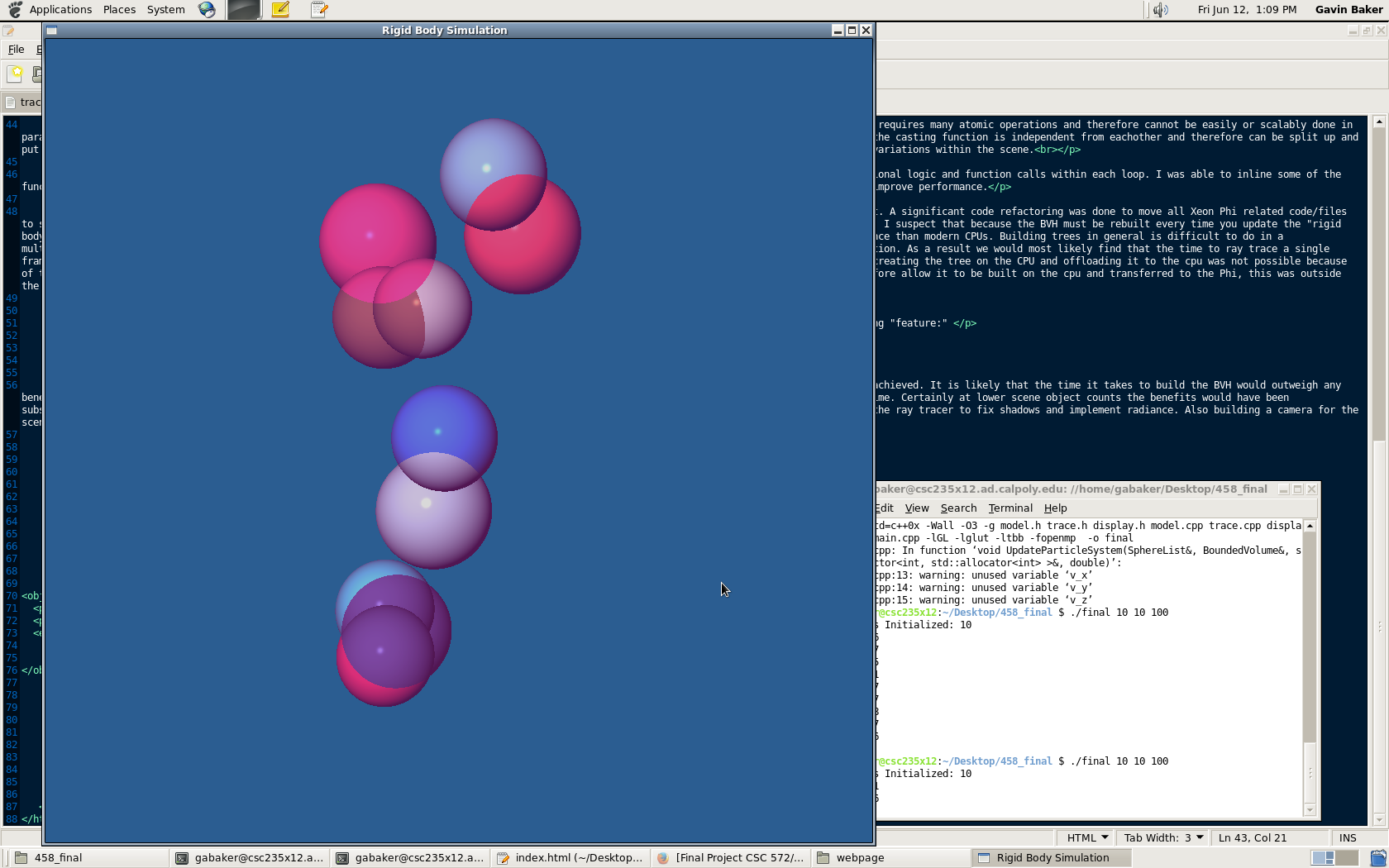
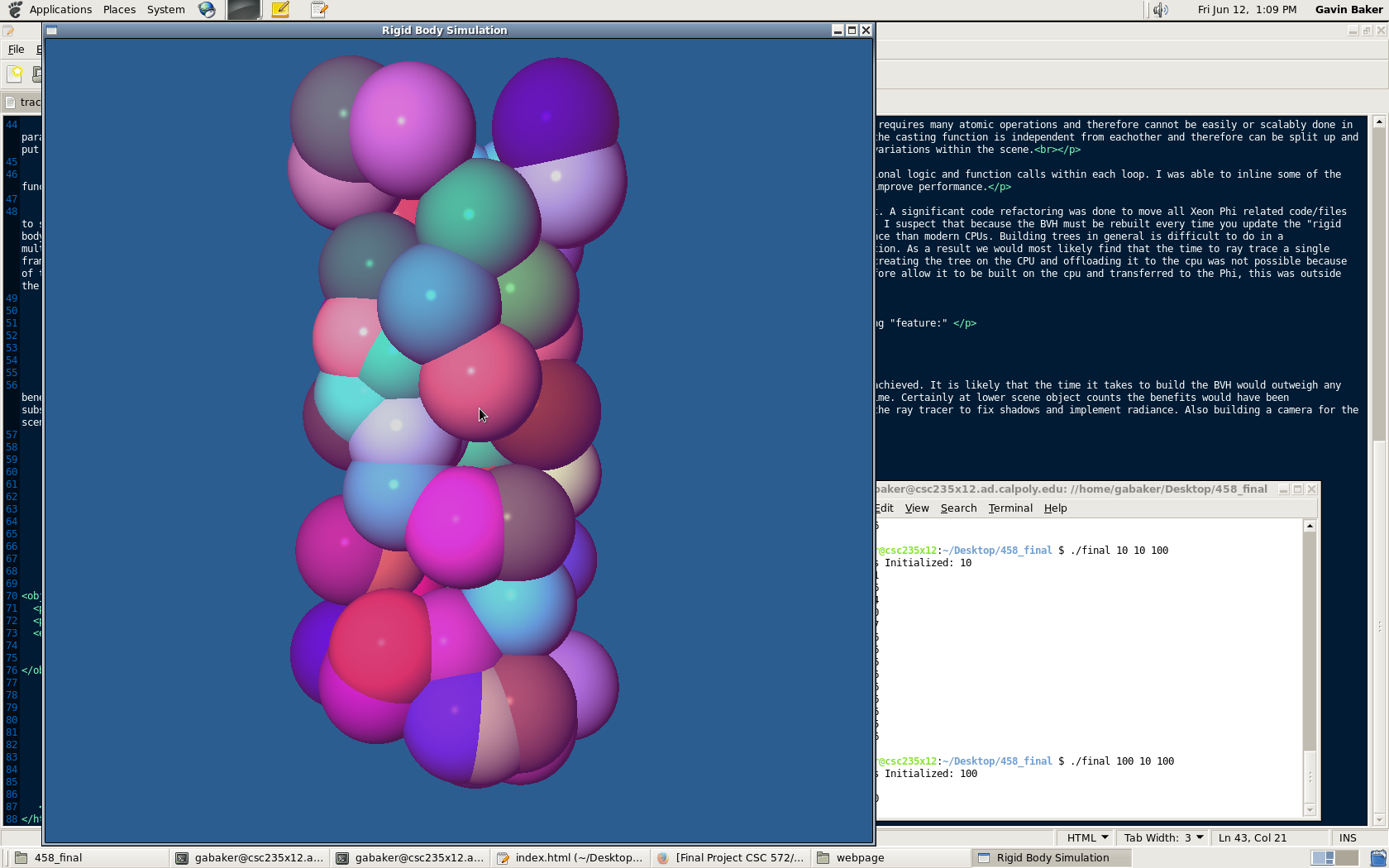
Sphere Radius = 100
Sphere Count = 10/100
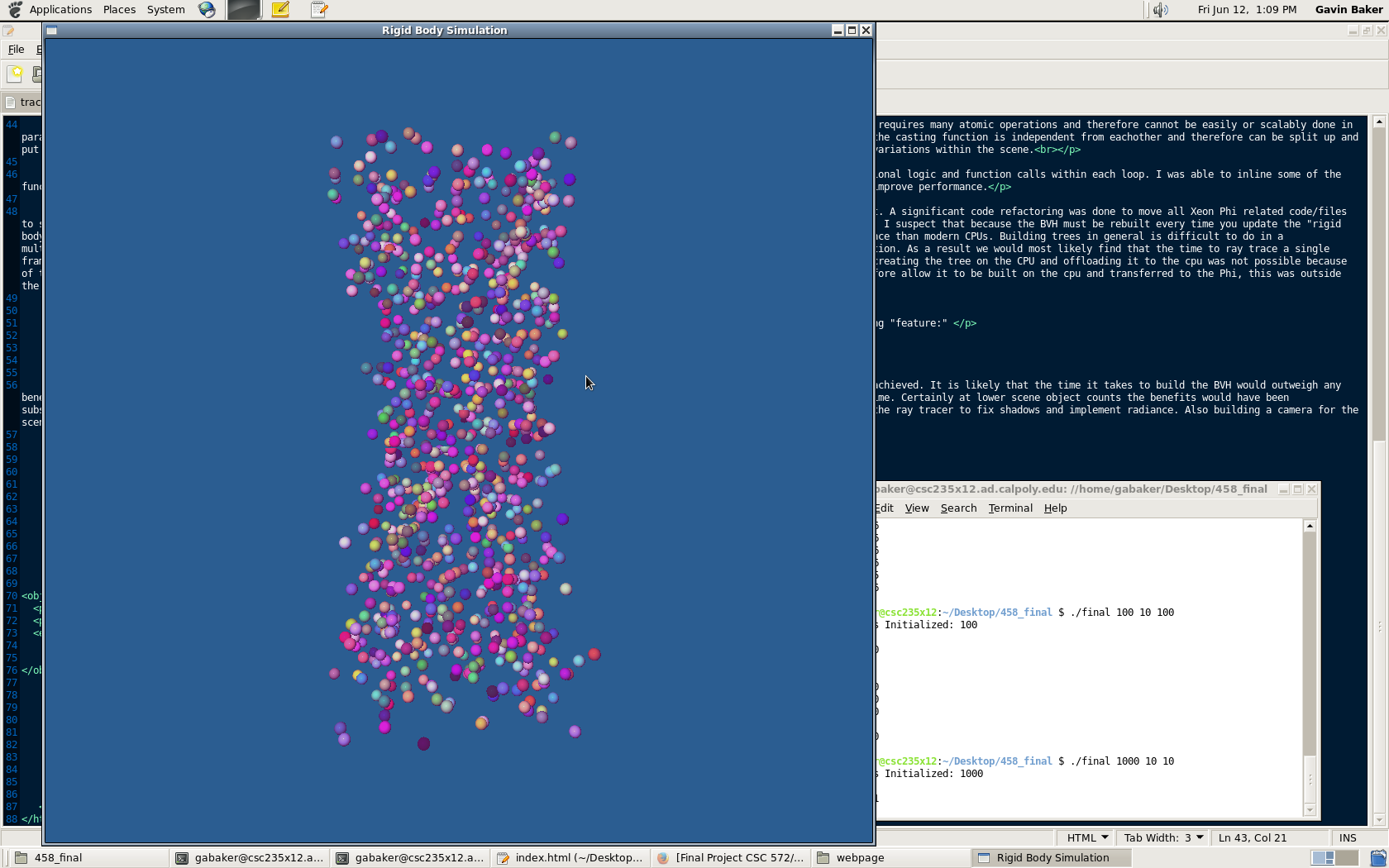
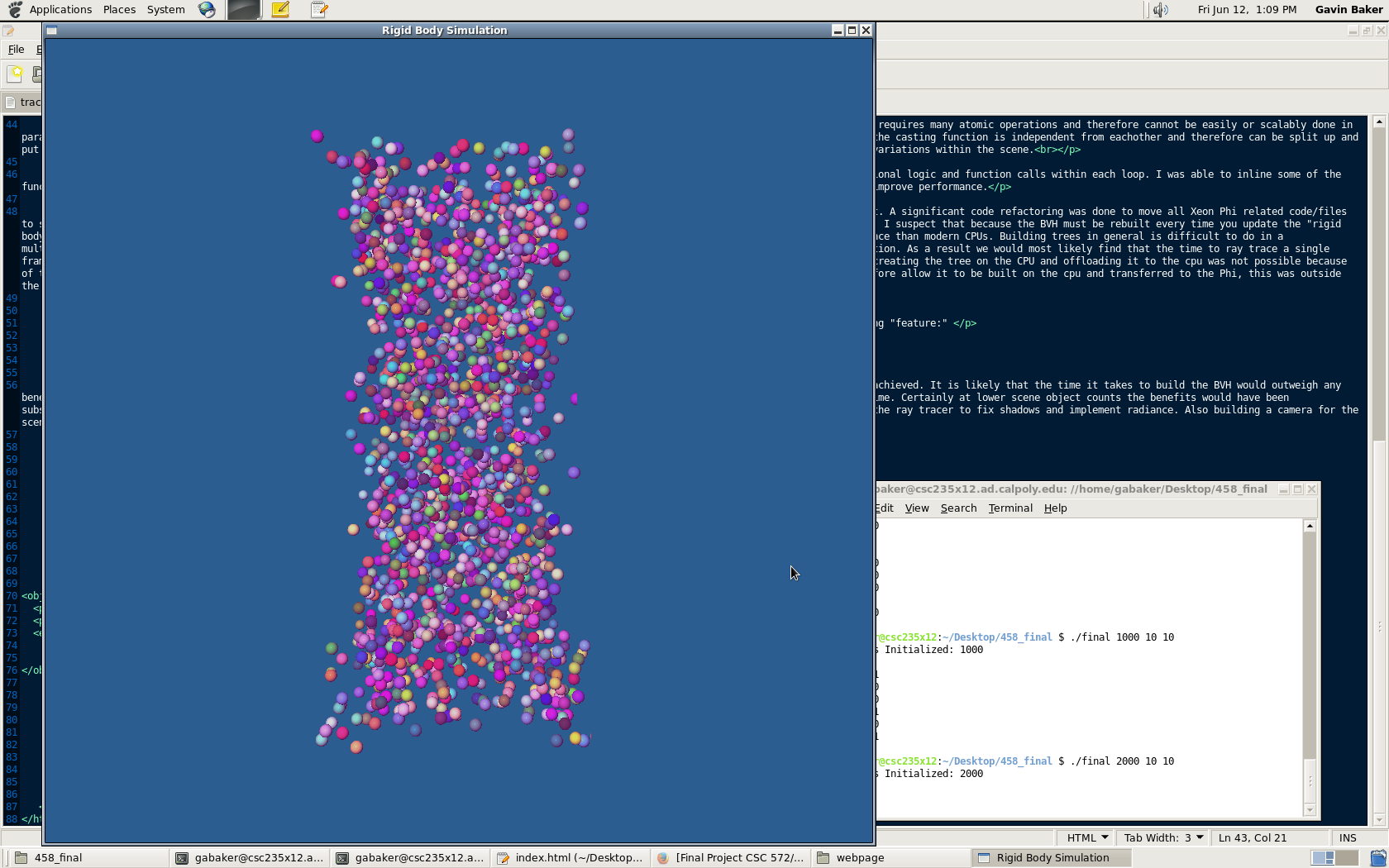
Sphere Radius = 10
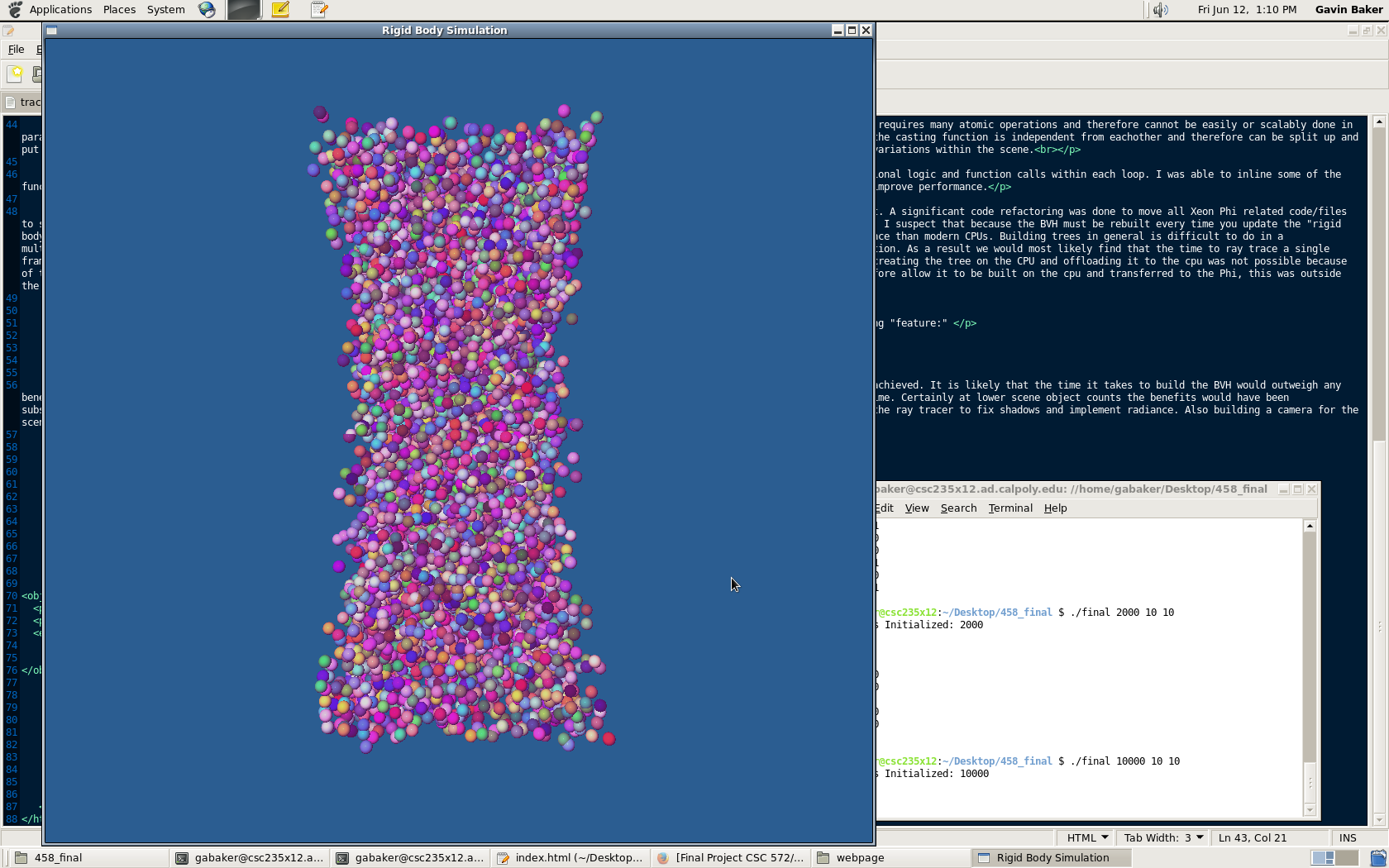
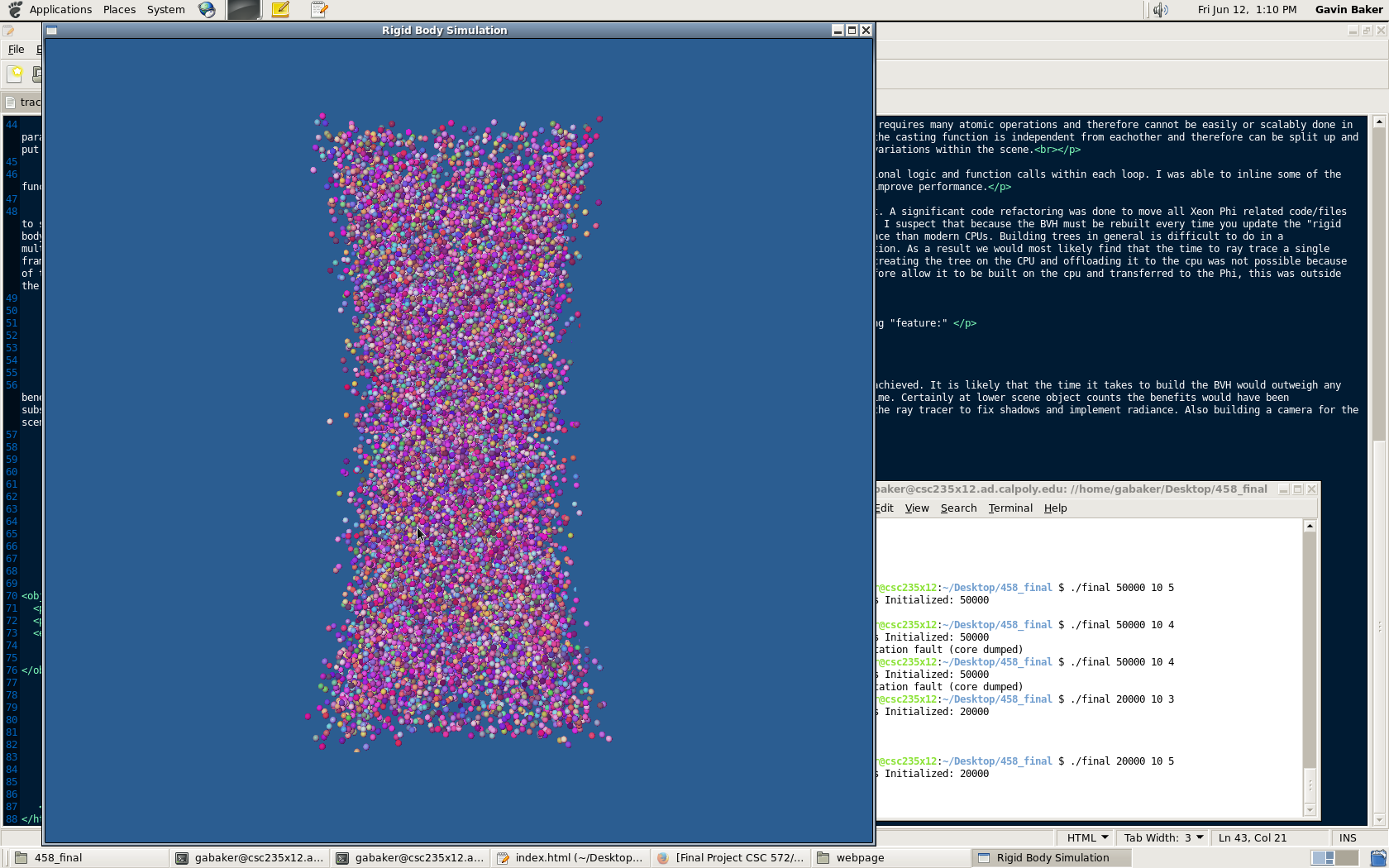
Sphere Count = 1000/2000
Left Sphere Radius = 10 Right Sphere Radius = 5
Sphere Count = 10,000/20,000