
This is a particle physics simulator written in C++ and OpenGL and optimized for modern multi-threaded and SIMD CPUs. This simulator computes the center of mass from all of the particles on the screen, and applies an acceleration towards the center for each of the particles. These particles can collide with each other, causing them to bounce and trade momentum. The simulation is encased in a bounding cube to prevent the simulation from drifting away from the center of the screen. The particles are spheres which are being shaded and rendered on-screen. The particle collisions cause the particles to change color, serving as a collision indicator and artistic flair.
W - Move forward
A - Move backward
S - Move left
D - Move right
I - Look up
K - Look down
J - Look left
L - Look right
Up - Add 1,000 particles
Down - Remove 1,000 particles
Right - Add 100 particles
Left - Remove 100 particles

Center of mass is represented by the red sphere in the middle of the screen. Every particle has an acceleration in the direction of the computed center of mass. The yellow sphere at the top represents the light source. The simulation starts with 1,000 particles, and then increased to 2,000 particles. The simulation has been sped up by 3x.
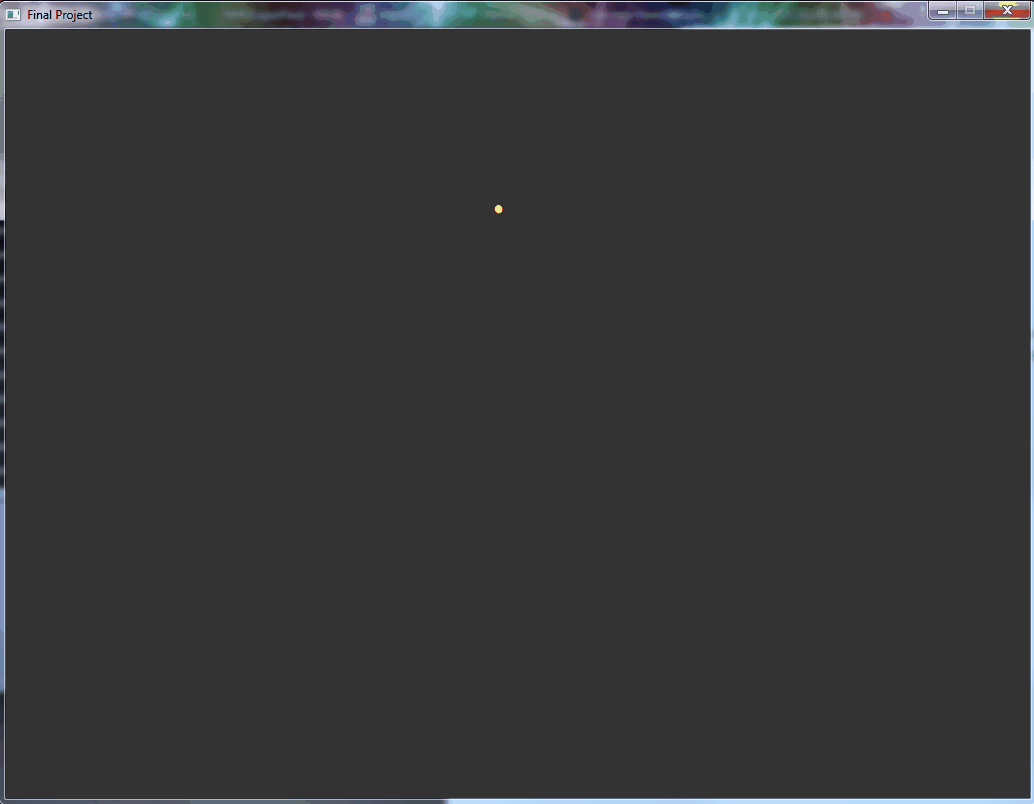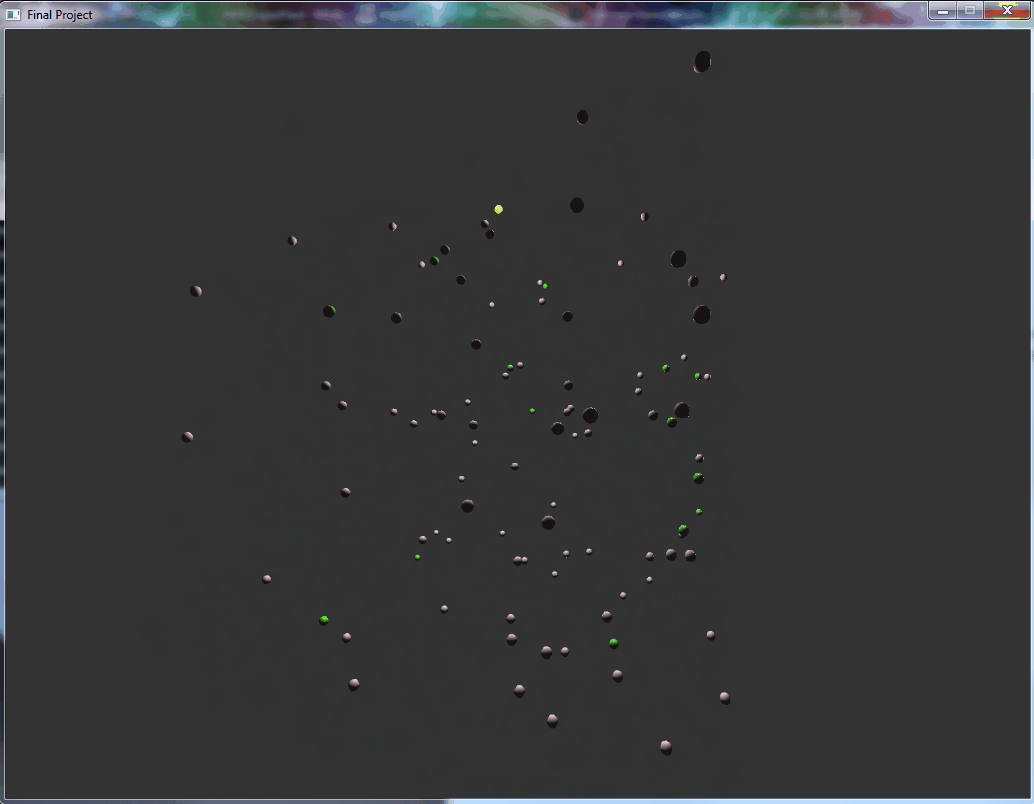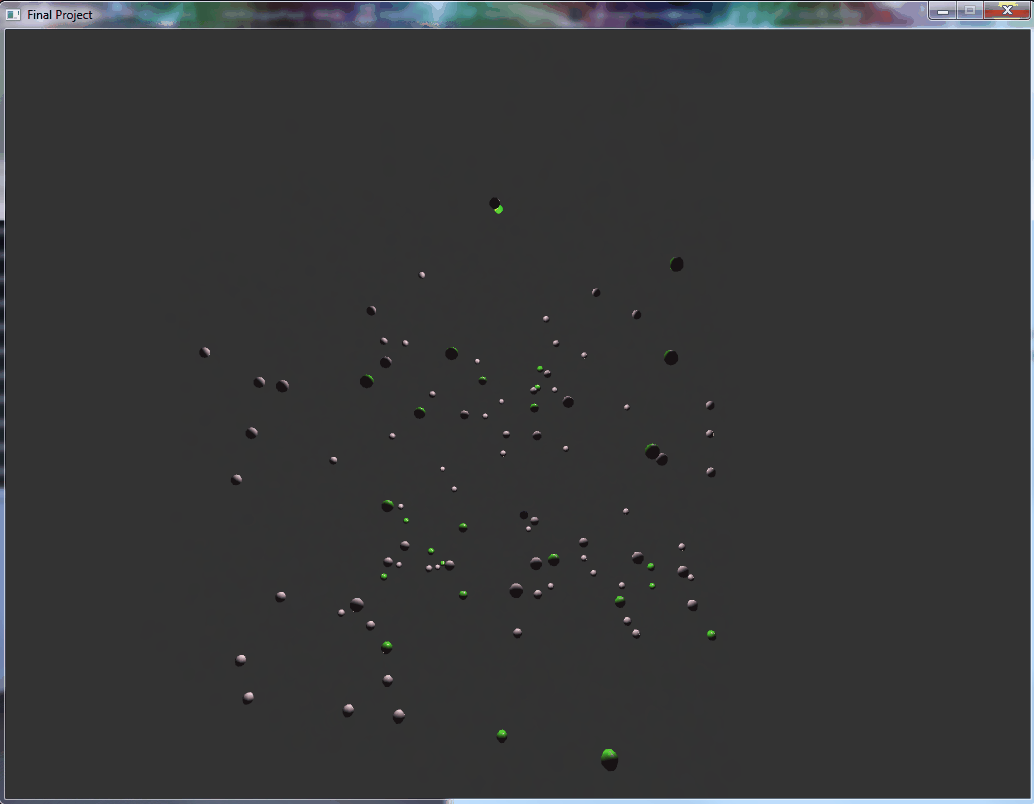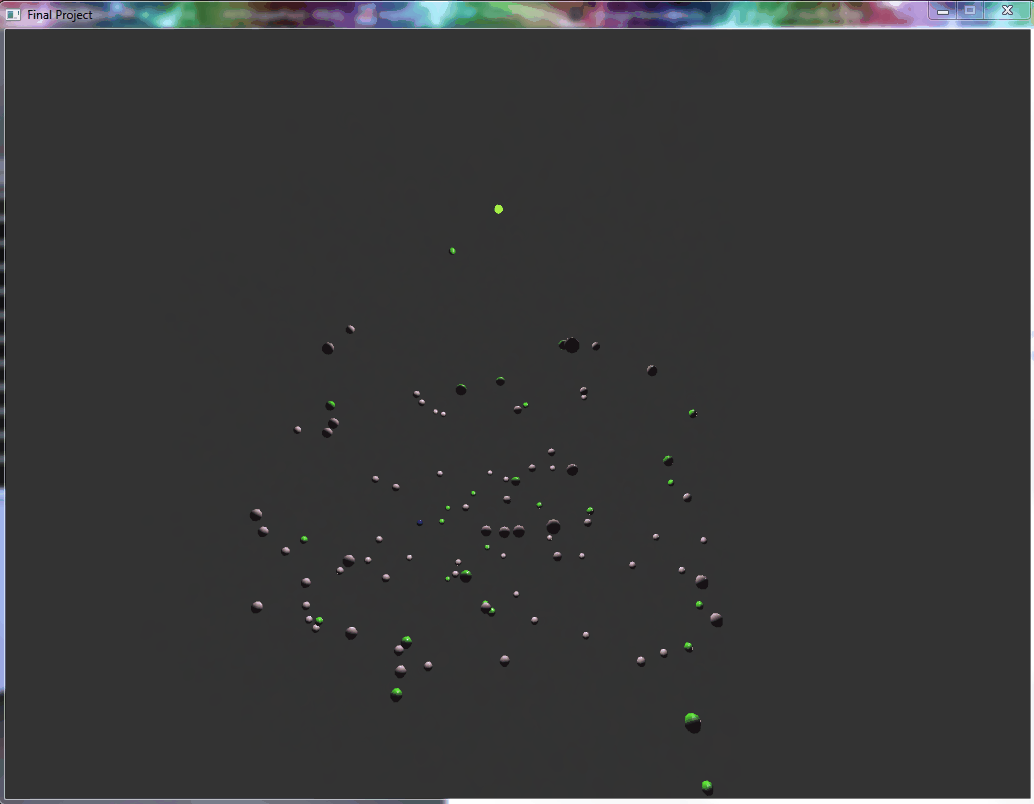
All particles have the same downward acceleration applied to them, creating a simulation of bouncing balls inside a box visualization. This simulation has not been sped up.
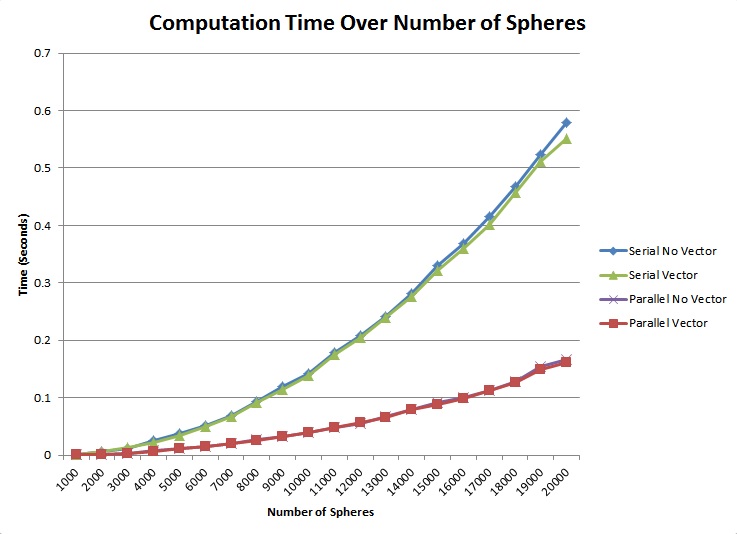
The program was tested on a laptop with an Intel Sandy Bridge 2630qm quad-core CPU with AVX instruction set and hyper-threading enabled and an NVidia 540m GPU. There is a noticeable performance curve between the serial and parallel versions of the program, while there isn't a noticeable difference in SIMD and scalar versions. This is likely due to the collision loop being unable to be vectorized. The collision loop is the most computationally intensive loop at a O(n^2), and therefore is the determinant in performance. There is roughly a 4x speedup from parallelization, which is the ideal performance improvement for a quad-core processor.
CPE 458 - Spring 2015 - Martin Watt